
前言
我对设计模式的理解是它就好像习武之人的内功,当内功强的人学习各种高深的武功就很得心应手,设计模式不同层次不同阶段的人对它的理解不同,我一直认为设计模式和算法一直是程序员两块非常重要的基本功,当基本功扎实就能对各种框架各种新技术驾轻就熟,会学习的很快,虽然在刚毕业的时候看过一遍设计模式,但感觉对它的理解还不够深,现在再重头回顾捋一遍。
设计模式的目的
设计模式为了保证程序具有更好的
- 代码重用性
相同的代码不需要多次编写 - 可读性
编程规范性,便于其他程序员的阅读和理解 - 可扩展性
当需要增加新的功能时,非常的方便,可维护 - 可靠性
当我们新增新的功能时,对原来的功能没有影响 - 灵活性
- 使程序呈现高内聚,低耦合的特性
模块与模块之间耦合度低,但模块之间相互配合功能高度聚合
设计原则
谈到设计原则想必我们都听过SOLID一词,他就是几个设计原则的首字母合并起来的简称,以前我对几个设计原则我都是死记硬背,但发现很容易忘记,当知道有SOLID这个单词的时候,脑开中每个字母联想一个单子就很容易记住这几个原则,S(单一职责原则)、O(开放封闭原则)、L(里式替换原则)、I(接口隔离原则)、D(迪米特法则),还有两个依赖倒转和合成复用原则。为什么设计模式要先谈设计原则呢?记得刚毕业面试的时候,面试官问我设计模式,我有时候嘴里会说出设计原则,然后面试官提醒我这是设计原则这不是设计模式,那么这两者是一个什么样的关系呢?后来我才知道23种设计模式万变不离其中,都是遵循这些设计原则的,下面我们弄清楚每一个设计原则。
单一职责原则(SRP)
单一职责原则的定义是对一个类来说,只负责一个职责或者功能。也就是说不要设计大而全的类,要设计力度小、功能单一的类。如果一个类包含两个或者两个以上的业务不相干的功能,那么说它的职责不够单一,应该将它拆分成多个功能单一的类、粒度更细的类。
单一职责原则注意事项和细节
- 降低类的复杂度,一个类只负责一项职责,一个方法只负责一个职责
- 提高类的可读性,可维护性
- 降低变更引起的风险
- 慎用很多分支的if else的分支判断,耦合度比较高
举个反例
一个玩家信息类这样设计1
2
3
4
5
6
7
8
9
10
11
12public class UserInfo
{
private long UserId;
private string UserName;
private string Emial;
private string PhoneNumber;
private string AvatarUrl;
private string Province; //省
private string City; //市
private string Region; //区
private string DetailAddress; //详细地址
}
咋一看感觉设计的还行,这个类包含了详细的玩家信息,但如果公司业务拓展,某个业务只需要玩家的一些基本信息用于app登录,并不关心玩家的详细住址,那么如果还用这个玩家信息的话就会有多余字段,而且这个地址信息在玩家信息中占的比重也是蛮大的,所以建议将地址信息抽出来单独变成一个Address类,UserInfo保留一个Address类的对象即可,如果不需要详细的地址信息这个对象可以保留为空,或者说将玩家的基本信息单独抽出来为UserBaseInfo,然后通过组合模式,组合成一个详细的玩家信息UserInfo也可以。
思考:类的职责是否越单一越好?
上面都在强调类的职责单一,那么是否是越单一越好呢?凡事过犹不及,答案是否定的,举例来说明:我们常用的序列化和反序列化,无论是哪种语言,序列化和反序列化的方法都在一个类里面,如果我们把序列化方法放在序列化的类里面,反序列化的方法放在反序列化类里面,经过拆分感觉Serializer类和Deserializer类职责更加单一了,但随之而来也带来新的问题,如果我们修改了协议或者序列化方式从JSON变成了XML,那么两个类都要做响应的修改,内聚性就没有原来的一个Serialization类高了,如果我们只修改了Serializer类而忘记了该Deserializer类的代码,那么就导致序列化、反序列化不匹配就会运行出错,也就是说拆分之后代码的可维护性变差了。
如何判断一个类职责是否单一?
不同的场景、不同的阶段的背景需求、不同的业务层面,对同一个类的职责是否单一,可能会有不同的判定结果。实际上,一些侧面的判断更具有指导意义和可执行性,比如,出现下面这些情况就有可能说明这个类不满足单一职责原则:
- 代码的行数、函数或者属性过多;
- 类依赖的其他类过多,或者依赖类的其他类过多;
- 私有方法过多;
- 比较难给类起一个合适的名字;
- 类中大量的方法都是集中操作类中某几个属性。
开放封闭原则
OCP开闭原则,对扩展开放,对修改关闭,这是编程中最基础、最重要的设计原则。当软件需求发生变化的时候,尽量通过扩展软件实体的行为为未来实现变化,而不是通过修改已有的代码来实现变化。
如何理解”对扩展开放、对修改关闭”?
添加一个新的功能,应该是通过在已有的代码基础上扩展代码(新增模块、类、方法、属性等),而非修改已有的代码(修改模块、类、方法、属性等)的方式来完成。关于定义,我们有两点需要注意。第一点是,开闭原则并不是说完全杜绝修改,而是以最小的改动代价来完成新功能的开发。第二点是,同样的代码改动下,在粗代码力度下,可能认定为”修改”,在细代码粒度下,可能又被认为是”扩展”。
如何做到”对扩展开放、对修改关闭”?
我们要时刻具备扩展意识、抽象意识、封装意识。在写代码的时候,我们要多花点时间思考一下,这段代码未来可能有哪些需求变更,如何设计代码结构,事先留好扩展点,以便在未来需求变更的时候,在不改动代码整体结构、做到最小代码改动的情况下,将新的代码灵活的插入到扩展点上。
很多设计原则、设计思想、设计模式,都是以提高代码的扩展性为最终目的的。特别是23中经典设计模式,大部分都是为了解决代码的扩展性问题而总结出来的,都是以开闭原则为指导原则的。最常用来提高代码扩展性的方法有:多态、依赖注入、基于接口而非实现编程,以及大部分的设计模式(比如,装饰、策略、模板、责任链、状态)。
里式替换原则
子类对象能够替换程序中父类对象出现的任何对象,并且保证原来的程序的逻辑行为不变及正确性不被破坏。这么一说有点跟多态类似,多态是面向对象编程的一大特性,也是面向对象编程语言的一种语法。它是一种代码实现思路。而里式替换是一种设计原则,是用来指导继承关系中子类该如何设计,子类的设计要保证在替换父类的时候,不改变原有程序逻辑以及不破坏原有程序的正确性。
哪些违背了里式替换原则的例子
子类违背父类声明要实现的功能
父类提供的订单排序函数,是按照金额从小到大给订单进行排序,而子类重写这个方法之后,是按照创建日期来给订单排序。那子类就违背了里式替换原则。
子类违背父类对输入、输出、异常的约定
在父类中,某个函数约定:运行出错的时候返回null,获取数据为空 到时候返回空集合(empty collection),而子类重载函数之后,实现变了,运行出错返回异常(exception),获取不到数据返回null。那这个子类的设计就违背了里式替换原则。
在父类中,某个函数约定,输入数据可以是任意整数,但子类实现的时候,只允许输入的数据是正整数,负数就抛出,也就是说,子类对输入的数据的校验比父类更加严格,那子类的设计就违背了里式替换原则。
在父类中,某个函数约定,只会抛出ArgumentNullException异常,那子类的设计实现中只允许抛出ArgumentNullException异常,任何其他异常的抛出,都会导致子类违背里式替换原则。
子类违背父类注释中所罗列的任何特殊说明
父类中定义的withdraw()提现函数的注释这么写:”用户的提现金额不得超过账户余额…”,而子类重写这个函数之后,针对VIP账户实现了透支提现的功能,也就是提现金额可以大于账户余额,那这个子类设计也是不符合里式替换原则的。
以上就是违背里式替换原则的大多数情况。除此之外,判断子类的设计是否违背里式替换原则,还有个小窍门就是拿父类的单元测试去验证子类的代码。如果某些单元测试运行失败,就有可能说明子类的设计没有遵循父类的约定,子类有可能违背了里式替换原则。
实际上,里式替换这个原则是非常宽松的,我们写代码的时候都不怎么会违背它,但或许有人少不注意也会违背它哦。
接口隔离原则(ISP)
接口隔离原则的英文翻译是”Interface Segregation Principle”,缩写ISP。英文意思是”Clients should not be forced to depend upon interfaces that the do not use.”翻译就是:客户端不应该强迫依赖它不需要的接口。其中的”客户端”可以理解为调用者或者使用者。
如何理解”接口隔离原则”?
理解”接口隔离原则”的重点是理解其中的”接口”二字。可以有三种不同的理解:
如果把”接口”理解为一组接口的集合,可以是某个微服务的接口,也可以是某个类库的接口等。如果部分接口只被部分调用者使用,我们就需要将这部分接口隔离出来,单独给给这部分调用者使用,而不强迫其他调用者也依赖这部分不会被调用到的接口。
如果把”接口”理解为单个API接口或函数,部分调用者值需要函数中的部分功能,那我们就需要把函数拆分成粒度更细的多个函数,让调用者只依赖它需要的那个细粒度函数。
如果把”接口”理解为OOP中的接口,也恶意理解为面向对象编程语言中的接口语法。那接口的设计要尽量单一,不要让接口的实现类和调用者,依赖不需要的接口函数。
接口隔离原则与单一职责原则的区别
单一职责原则针对的是模块、类、接口的设计。接口隔离原则相对于单一职责原则,一方面更侧重接口的设计,另一方面它的思考角度也是不同的。接口隔离原则则提供了一种判断接口的职责是否单一的标准:通过调用者如何使用接口来间接地判定。如果调用者只使用部分接口或接口的部分功能,那接口的设计就不够单一。
依赖倒转原则
基本介绍
- 高层模块不应该依赖低层模块,二者都应该依赖其抽象对象
- 抽象不应该依赖细节,细节应该依赖抽象
- 依赖倒转(倒置)的中心思想是面向接口编程
- 依赖倒转原则是基于这样的设计理念:相对于细节的多变性,抽象的东西要稳定的多。以抽象为基础搭建的架构比以细节为基础的架构要稳定的多。在C#中,抽象指的是接口或抽象类,细节就是具体实现的类
- 使用接口或抽象类的目的是定制好规范,而不涉及任何具体的操作,把展现细节的任务交给他们的实现类去完成
依赖关系传递的三种方式
- 接口传递
- 构造方法传递
- setter方法传递
之前有写过一篇依赖倒置的详细文章,可以点击看一下。
控制翻转、依赖翻转、依赖注入的关系和联系
控制反转
控制反转是一个比较笼统的设计思想,并不是一种具体的实现方法,一般用来指导框架层面的设计。这里所说的”控制”指的是对程序执行流程的控制,而”反转”指的是在没有使用框架之前,程序员自己控制整个程序的执行。在使用框架之后,整个程序的执行流程通过框架来控制。流程的控制权从程序员”反转”给了框架。依赖注入
依赖注入与控制反转恰恰相反,它是一种具体的编程技巧。我们不通过new的方式在类的内部创建依赖类的对象,而是将依赖的类的对象在外部创建好之后,通过构造函数、函数参数等方式传递(注入)给类来使用。依赖注入框架
我们通过依赖注入框架提供的扩展点,简单配置一下所有需要的类及其类与类之间依赖关系,就可以实现由框架来自动创建对象、管理对象的生命周期、依赖注入等原本需要程序员来做的事情。依赖反转原则
依赖反转原则也叫做依赖倒置原则。这条原则跟控制反转有点类似,主要是用来指导框架层面的设计。高层模块不应该依赖低层模块,它们共同依赖同一个抽象。抽象不要依赖具体实现细节,具体实现细节依赖抽象对象。
迪米特法则
迪米特法则又叫”最少知道原则”,即一个类对自己依赖的类知道的越少越好。每个模块(unit)只应该了解那些与它关系密切的模块的有限知识。或者说,每个模块之和自己的朋友”说话”(talk),不和陌生人”说话”(talk)。”不该有直接依赖关系的类之间,不要有依赖”。”有依赖关系的类之间,尽量只依赖必要的接口”
如何理解”高内聚、低耦合”
“高内聚、松耦合”是一个非常重要的设计思想,能够有效提高代码的可读性和可维护性,缩小功能改动导致的代码改动范围。”高内聚”用来指导类本身的设计,”低耦合”用来指导类与类之间依赖关系的设计。
所谓高内聚,就是指相近的功能应该放到同一个类中,不想近的功能不要放在同一个类中。相近的功能旺旺会被同时修改,放到同一个类中,修改比较集中。所谓低耦合指的是,在代码中,类与类之间的依赖关系简单清晰。即使两个类有依赖关系,一个类的代码改动也不会或者很少导致依赖类的代码改动。
如何理解”迪米特法则”
不该有直接依赖关系的类之间,不要有依赖;有依赖关系的类之间,尽量只依赖必要的接口。迪米特法则是希望减少类之间的耦合,让类越独立越好。每个类都应该少了解系统的其他部分。一旦发生变化,需要了解这一变化的类就会比较少。
迪米特法则有一个更简单的定义:只跟直接朋友通信。
直接的朋友:每个对象都会与其他对象有耦合关系,只要两个对象之间有耦合关系,我们就说这两个对象之间是朋友关系。耦合的方式很多,依赖、关联、组合、聚合等。其中,我们称出现成员变量,方法参数,方法返回值中的类为直接的朋友,而出现在局部变量中的类不是直接的朋友。也就是说,默认的类最好不要以局部变量的形式出现在的类的内部。
迪米特法则注意事项
1) 迪米特法则的核心是降低类之间的耦合。
2)但是注意:由于每个类都减少了不必要的依赖,因此迪米特法则只是要求降低类之间(对象间)耦合关系,并不是要求完全没有依赖关系。
合成复用原则
原则是尽量使用合成/聚合的方式,而不是使用继承。
举例:如果A类有两个方法,要让B类能够使用这两个方法,我们可以将B继承自A,那么B类就可以使用A类的两个方法,这样就增强了他们的耦合性。但如果A类还有其他方法,但B类并不需要用,那就不太适合。还有一种方案就是让B依赖A,通过参数将A的对象传进来(依赖),或者B类添加一个A类的属性(聚合),或者setter方法,又或者在B类实例化一个A类的对象(组合),这些都是设置依赖方式,如下图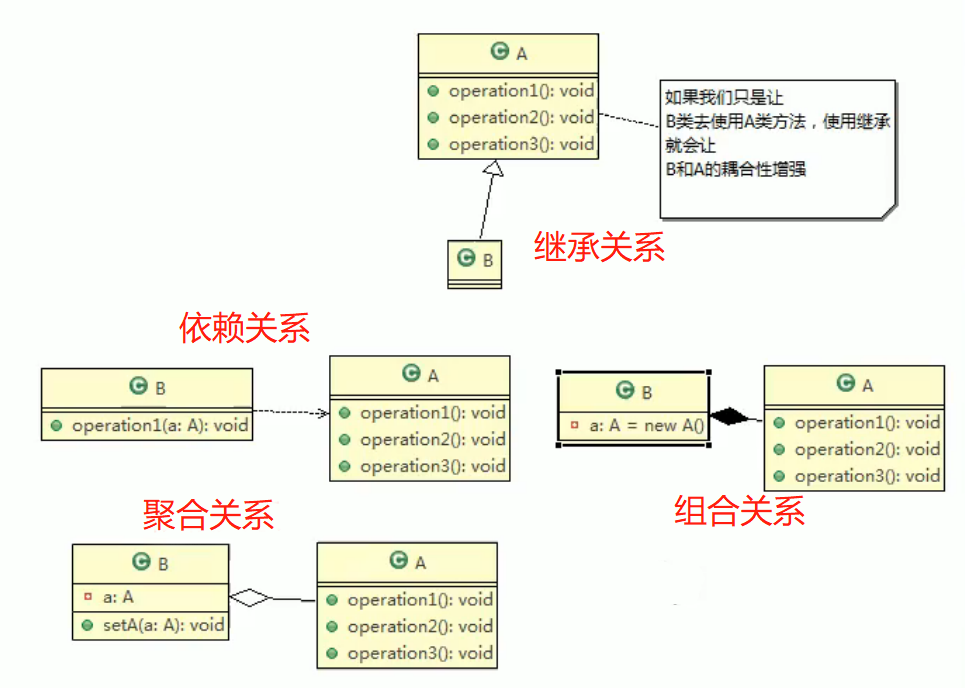
设计模式系列教程汇总
http://dingxiaowei.cn/tags/设计模式/

